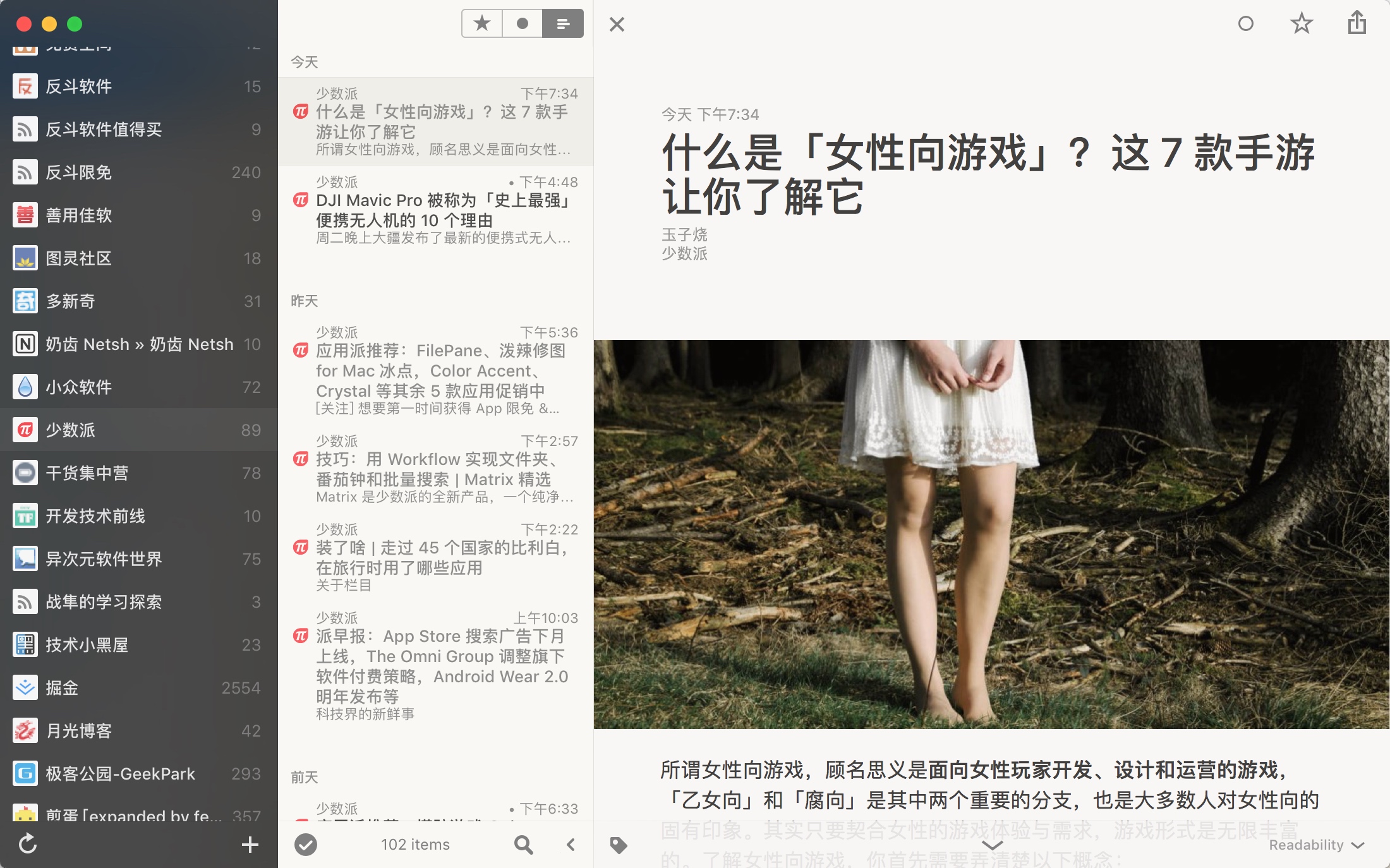
阅读是一个主动寻求知识的过程,在如今碎片信息充斥着我们生活中的时代,我们需要清楚自己想要获取什么,把有限的时间放在消化信息上,而不是放在获取信息的途径上。如今我们可以通过各种 APP、公众号、聚合信息网站获取相对大众并符合自己的信息,但也有缺点:我需要下载这么多个 APP 去看新闻和文章吗?这些网站就拥有所有我想知道的吗?当然,像「即刻」、「Flipboard」这种阅读聚合类应用适当地缓解了这样的矛盾,但是这些信息源真的已经足够适合自己了吗?当初我找到了解决方法,也一直使用到现在,这个方法就是订阅 RSS 源。
本篇文章将简介 RSS,初步订阅适合自己的 RSS 源,并对于一部分不提供 RSS 订阅的网站,我们为其创建 RSS 源并订阅。
RSS
RSS(Really Simple Syndication,简易信息聚合)是一种消息来源格式规范,表达了「聚合真的很简单」这样的愿景,我们可以将其看作是一种定制个性化推送信息的服务。
macOS 客户端
我推荐 Reeder 3,因其功能足且美观,还支持iOS平台,付费。

另外 Leaf 也不错。
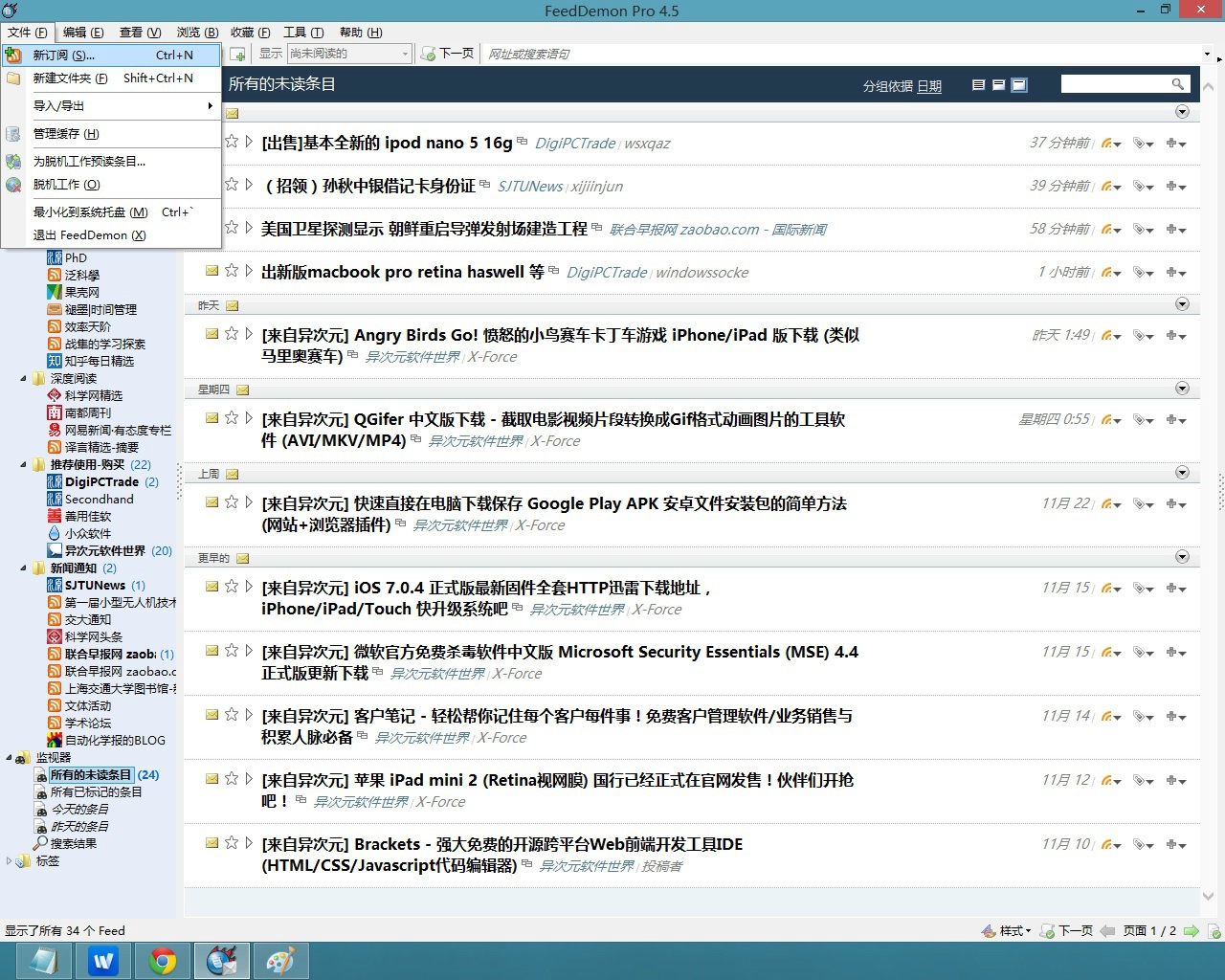
Windows 客户端
自己不使用 Windows,根据你必读的 RSS 订阅源有哪些?不负责地推荐 FeedDemon。
其他平台
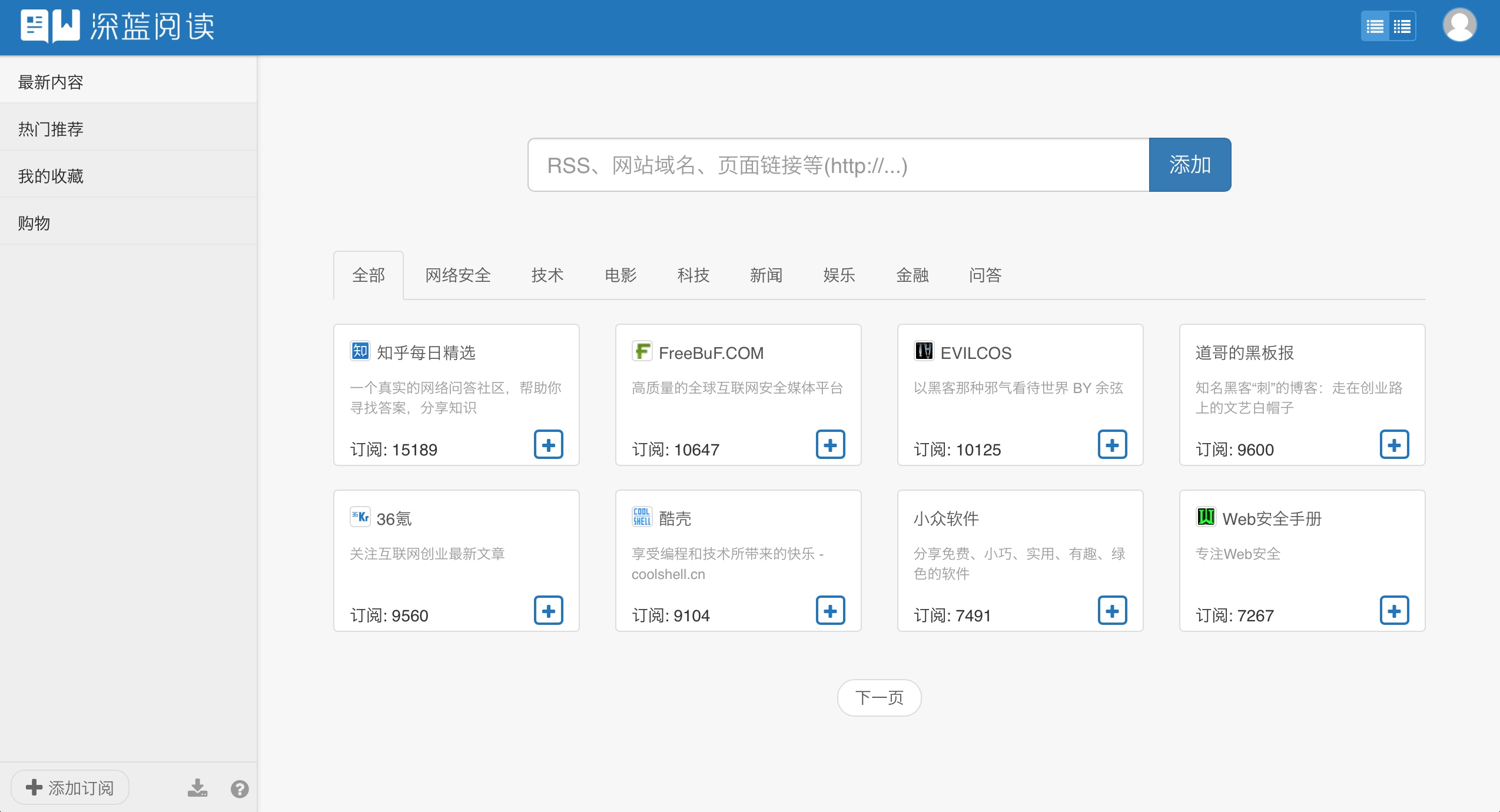
RSS 平台提供了更广泛的服务,例如查找网站的 RSS 源并订阅,查看热门订阅源,管理分类订阅源等。优秀的 RSS 平台有 Feedly、Inoreader 等,由于不可描述的原因,国内这些平台连接速度会较慢,所以我给了一下两种推荐:
入门的话推荐国产的深蓝阅读,支持 iOS、Android 平台。
✨进阶推荐 Inoreader 官网 评测
Inoreader 也支持 iOS、Android、Windows Phone 平台,也有对应的浏览器插件。
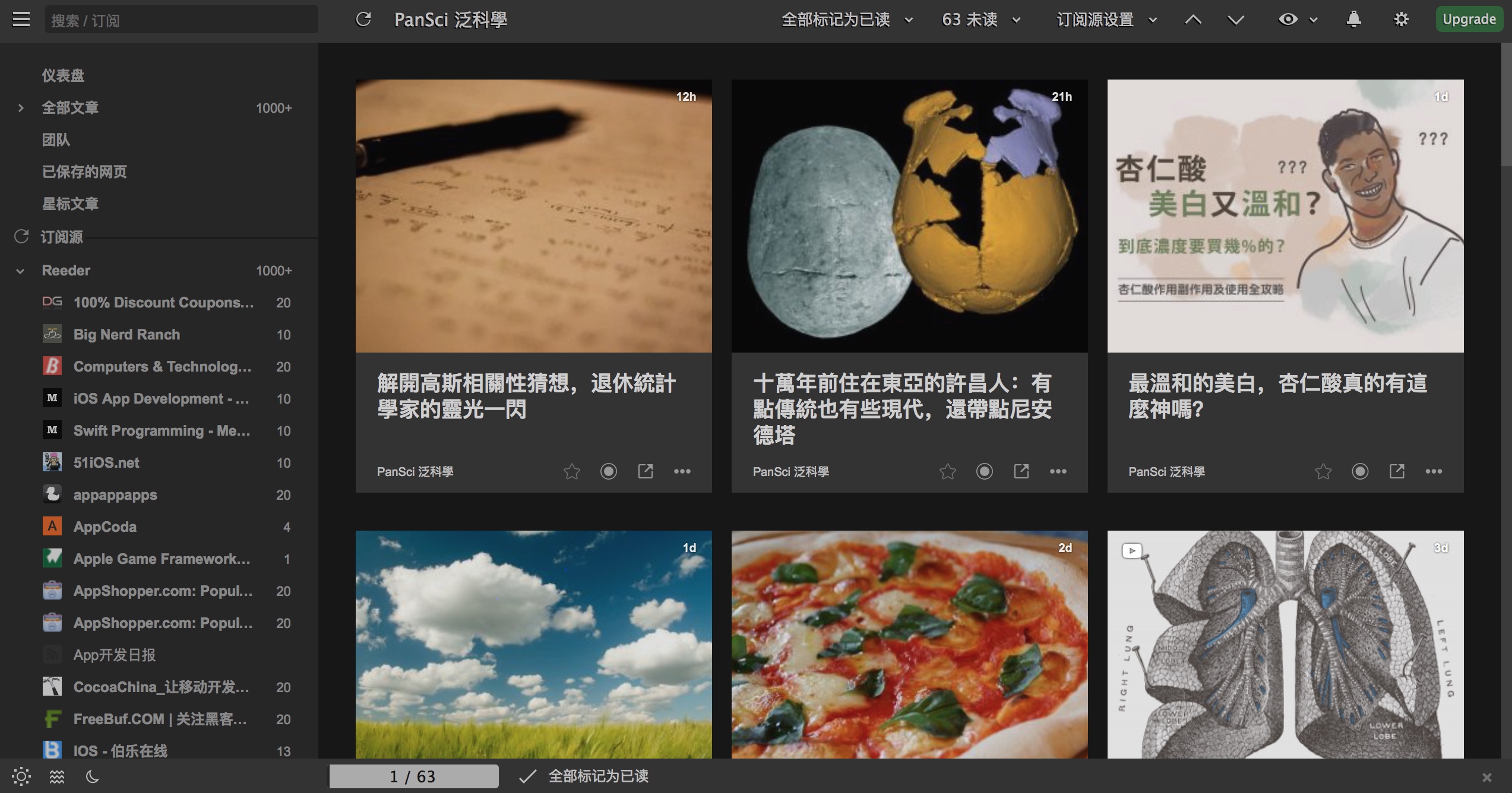
Ioreader 推荐的第三方 RSS 阅读器。
RSS 阅读器只是显示 RSS 内容的一个平台,因此选自己喜欢的就好,我们的重点是如何获取适合自己的 RSS 源。
RSS源
常见网站 RSS 订阅位置
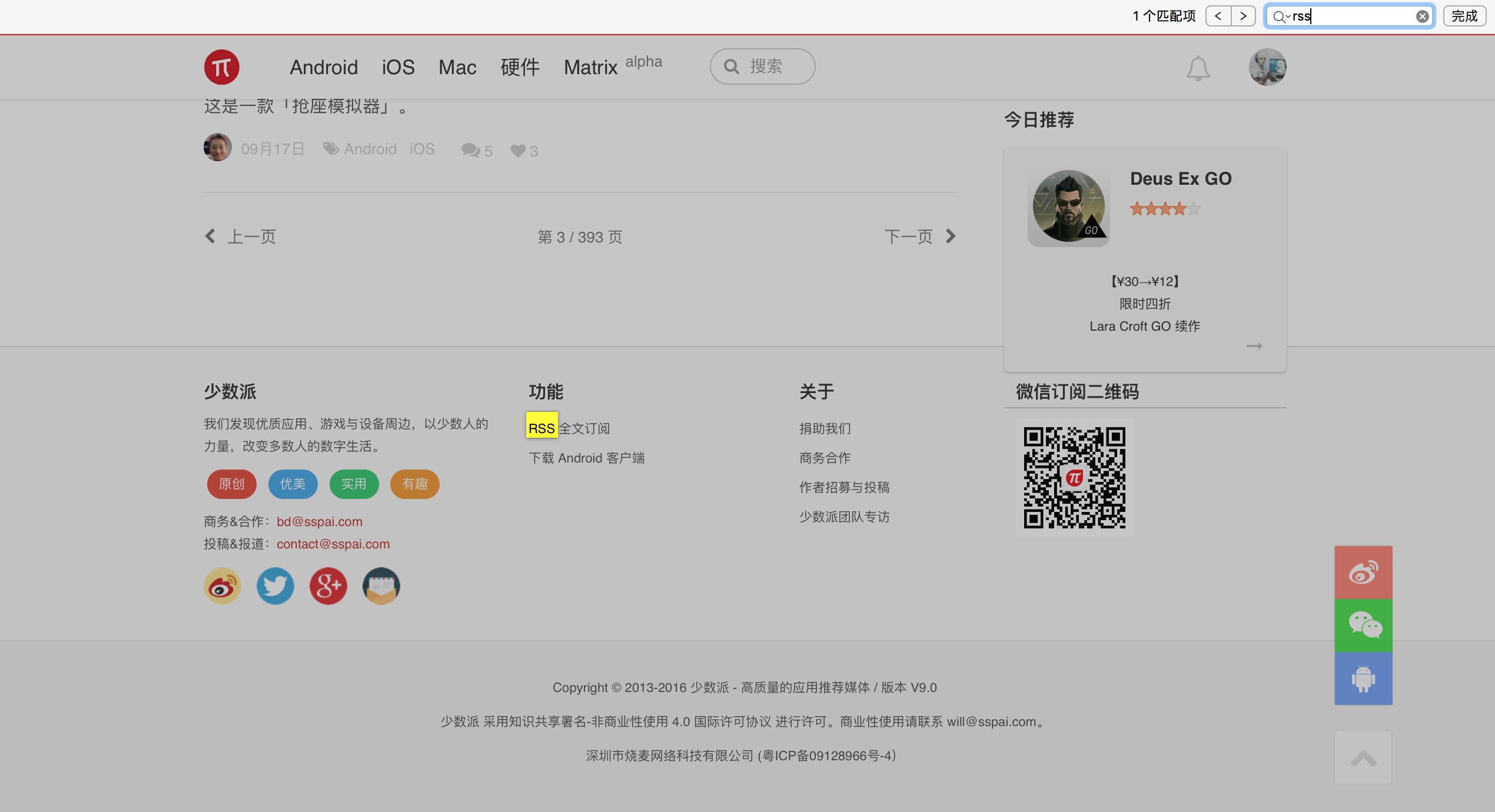
我们可以再去到自己常去的网站,看看有没有提供RSS订阅。例如少数派首页,我搜索rss,就找到了RSS源。
再例如在一些博客中,WIFI 一样的图标就是 RSS 订阅地址,不认识的话现在就记下来吧~

我们可以直接复制链接地址到阅读器中,这样就能简单的订阅 RSS 了。
播客
Feed Flipper 可以把 iTunes 的播客链接转成 RSS 源地址。
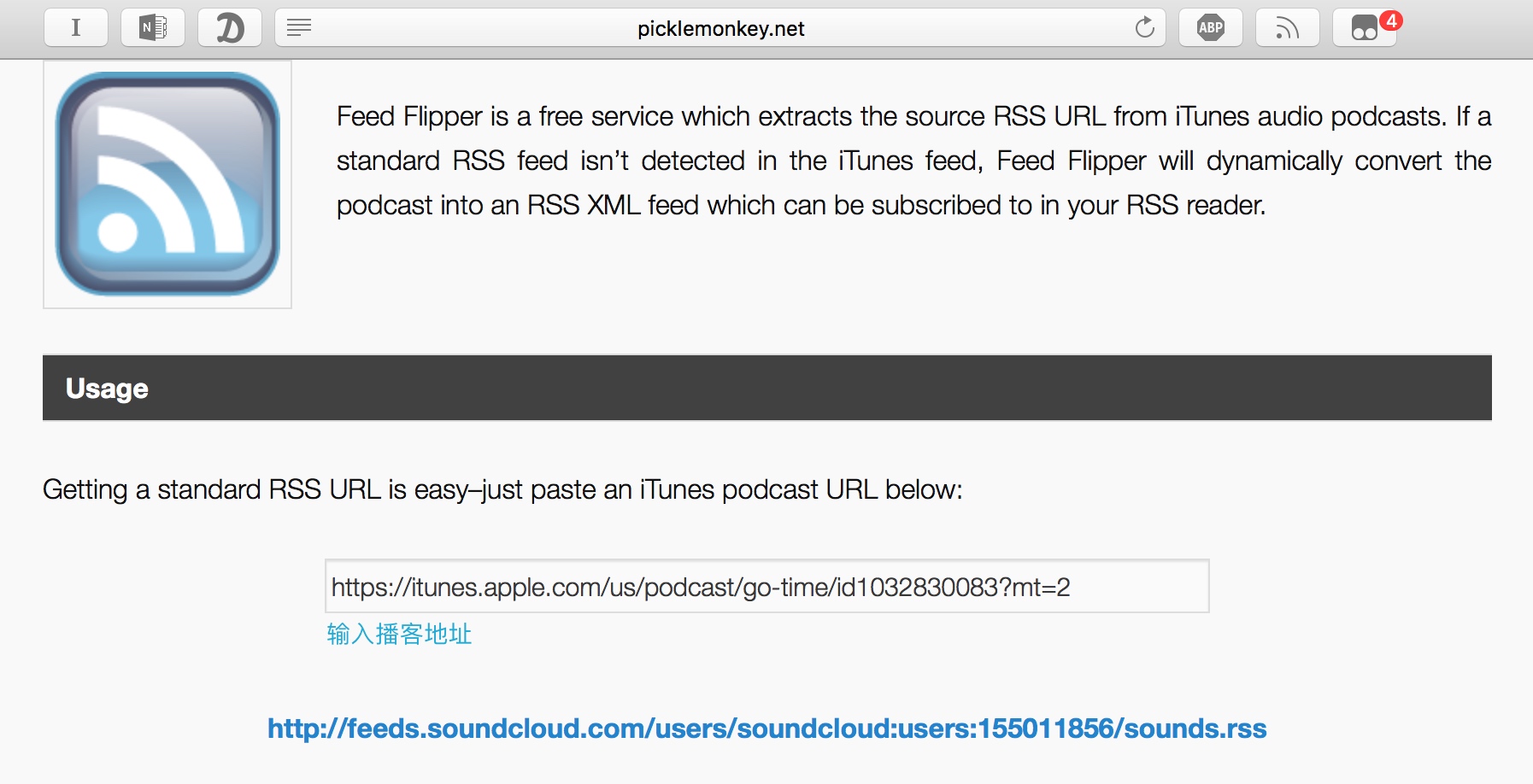
作者另外一个项目 Cloud Flipper 能把 SoundCloud 转成 RSS。
关于中文播客网站的订阅可以参考如何获取喜马拉雅、荔枝FM、考拉FM等中文播客RSS源。
Medium
Medium 是国外版的「简书」,里面有很多独特而优质的内容和天才般的作家,单独拿出来讲是因为我实在是太喜欢 Medium 了!

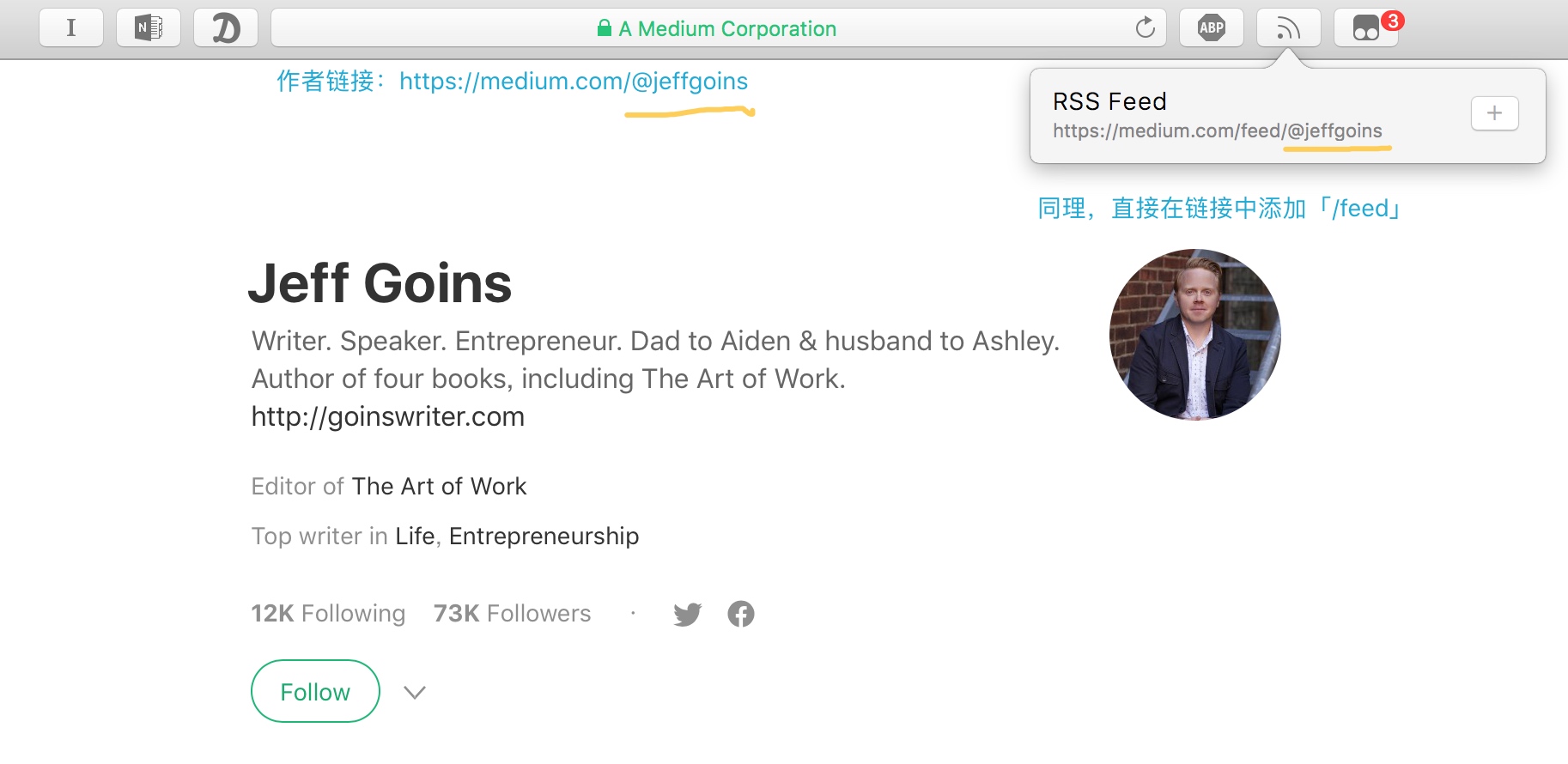
注:这里使用的是 Safari 插件(macOS 专属)—— Syndicate
RSS 搜索利器
如果不依赖平台自带的 RSS 源搜索功能,我们也有其他选择。
浏览器插件
前面介绍了 Safari 的 RSS 源查找插件 Syndicate,这里介绍一个 Chrome 浏览器的插件——RSS Subscription Extension。

微广场
微广场提供微信公众号的RSS订阅,免费用户可订阅10个内容源。

RSS源推荐
你必读的 RSS 订阅源有哪些? 这里已经总结了很多优秀的订阅源。
例如:
| 名称 | RSS地址 |
|---|---|
| 知乎每日精选 | http://www.zhihu.com/rss |
| 读书笔记 | http://www.write.org.cn/feed |
| 褪墨 | http://feed.mifengtd.cn/ |
不再阐述太多,适合自己的才是最好的。
创建RSS源
部分网站可能比较看重 PV 值,就是希望用户主动进入他们的网站,或者其他原因不提供 RSS 源,这时候就需要我们使用 feed43 的服务来为我们扫平障碍。国内网站似乎不太热衷主动提供 RSS 订阅地址,这点国外做的较好。
Step 1
首先点进 feed43 右上角 Create Account 注册,登录完之后到主页点击 Create new feed 来创建自己的RSS源。接下来我将会用科学人|果壳网来做示范。
我们把http://www.guokr.com/scientific/复制进 Step 1的 Address,编码会自动选择,如果出现乱码可以尝试utf-8或其他编码,之后点击 Reload。
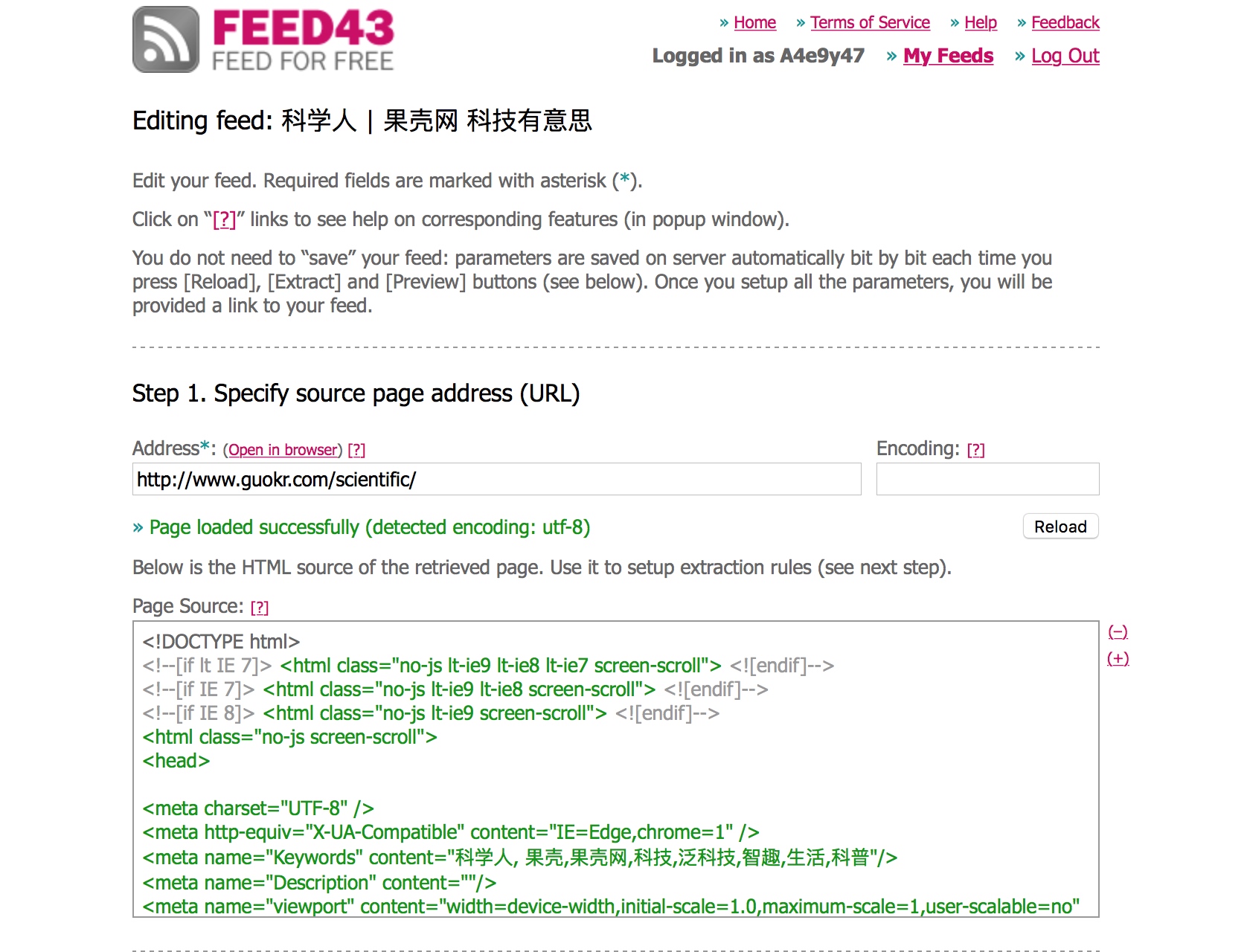
Step 2
我们可以看到页面的源码,看到这不要慌,这些都有套路。
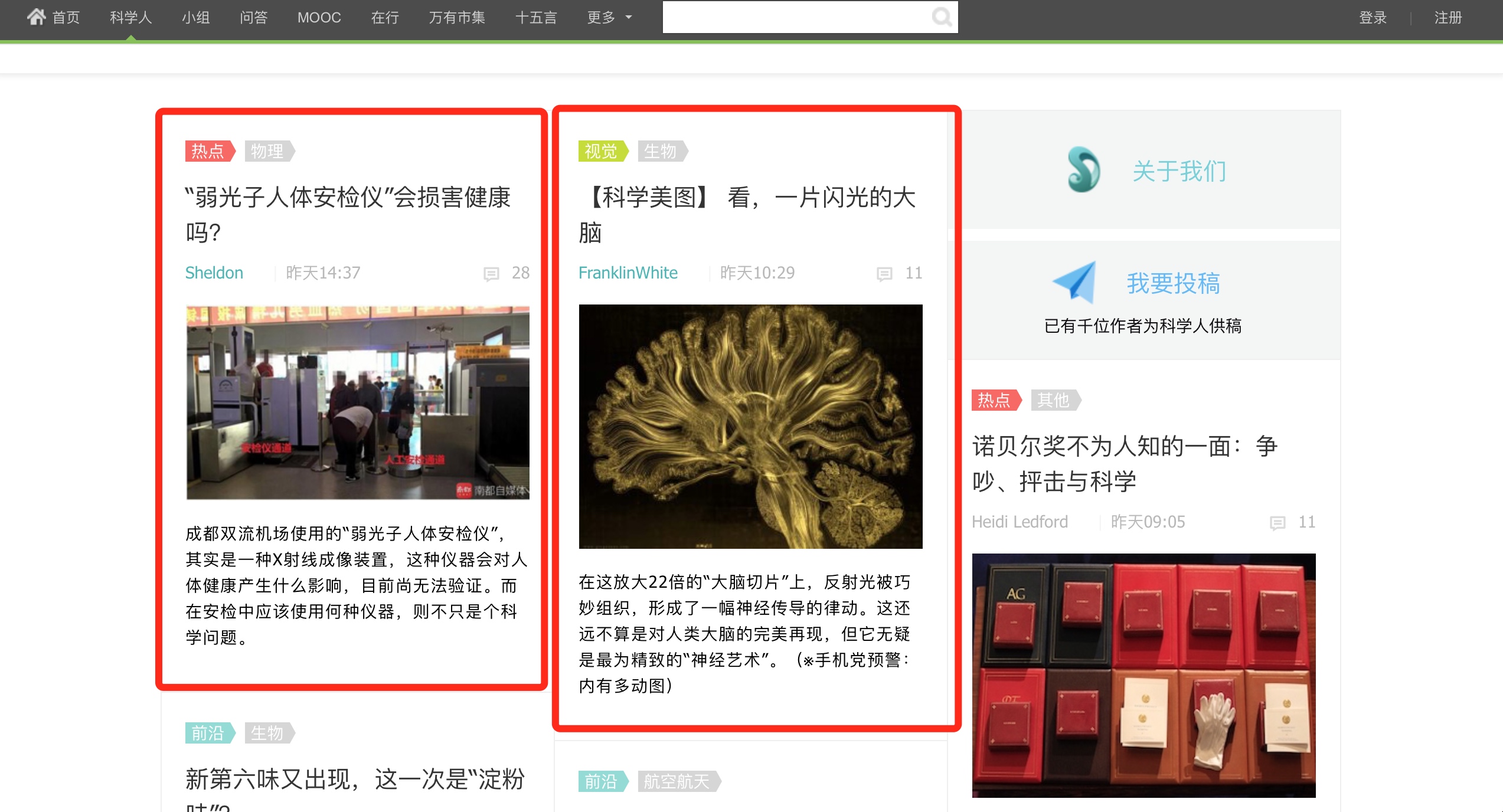
像上面的图一样,红框中就是我们想要获取的单条信息。其中文章都是一块一块的,样子一样,变的只是其中的文字内容、图片地址,所以相应的代码块也是相似的。我们要清楚的就是想要获取的信息,例如:标题、图片、简介。
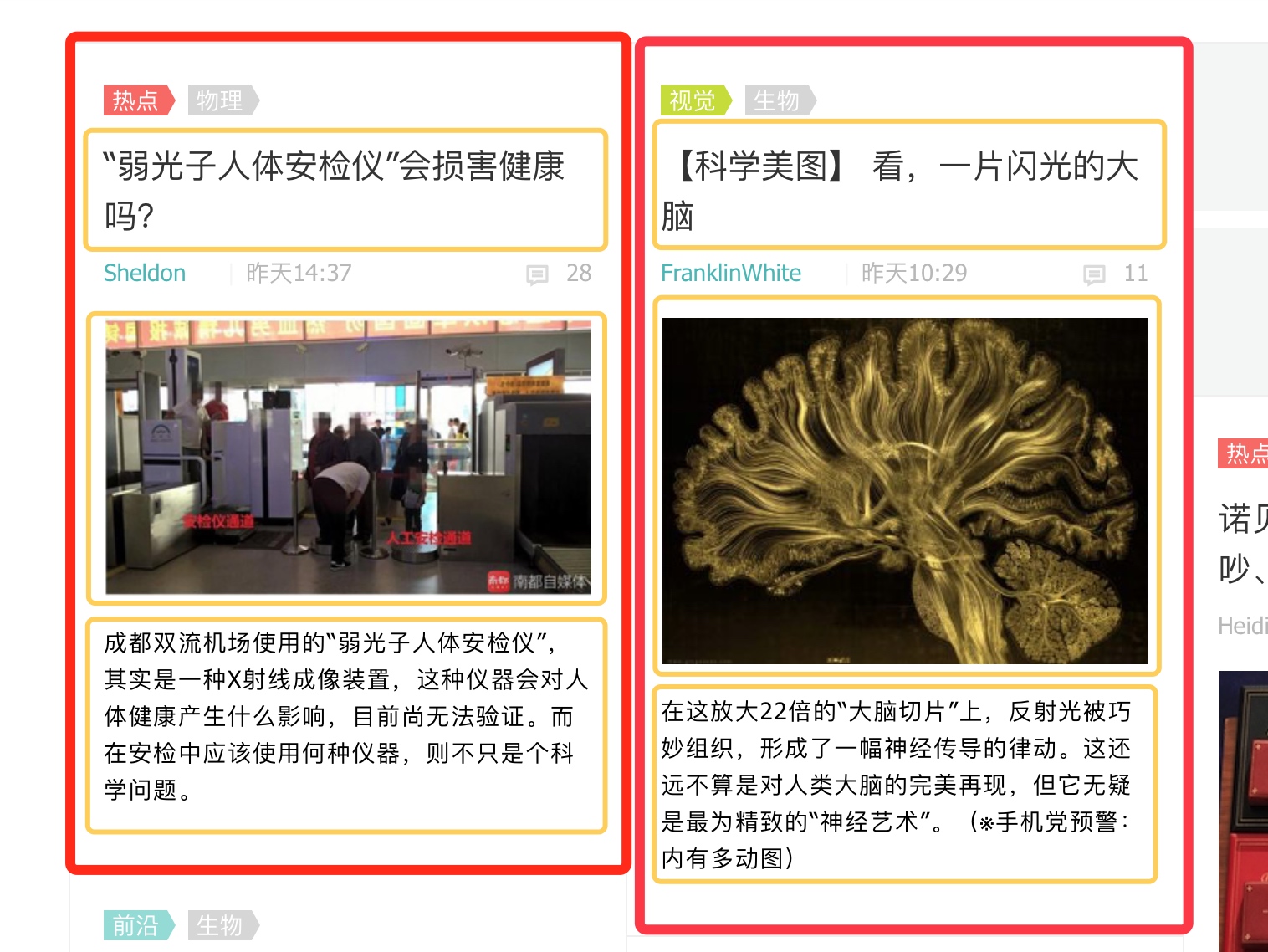
网页源代码是一层一层的,我们首先定位到大红框单个文章块的代码块。简单点可以直接 Ctrl+F 查询其中的标题,例如弱光子。
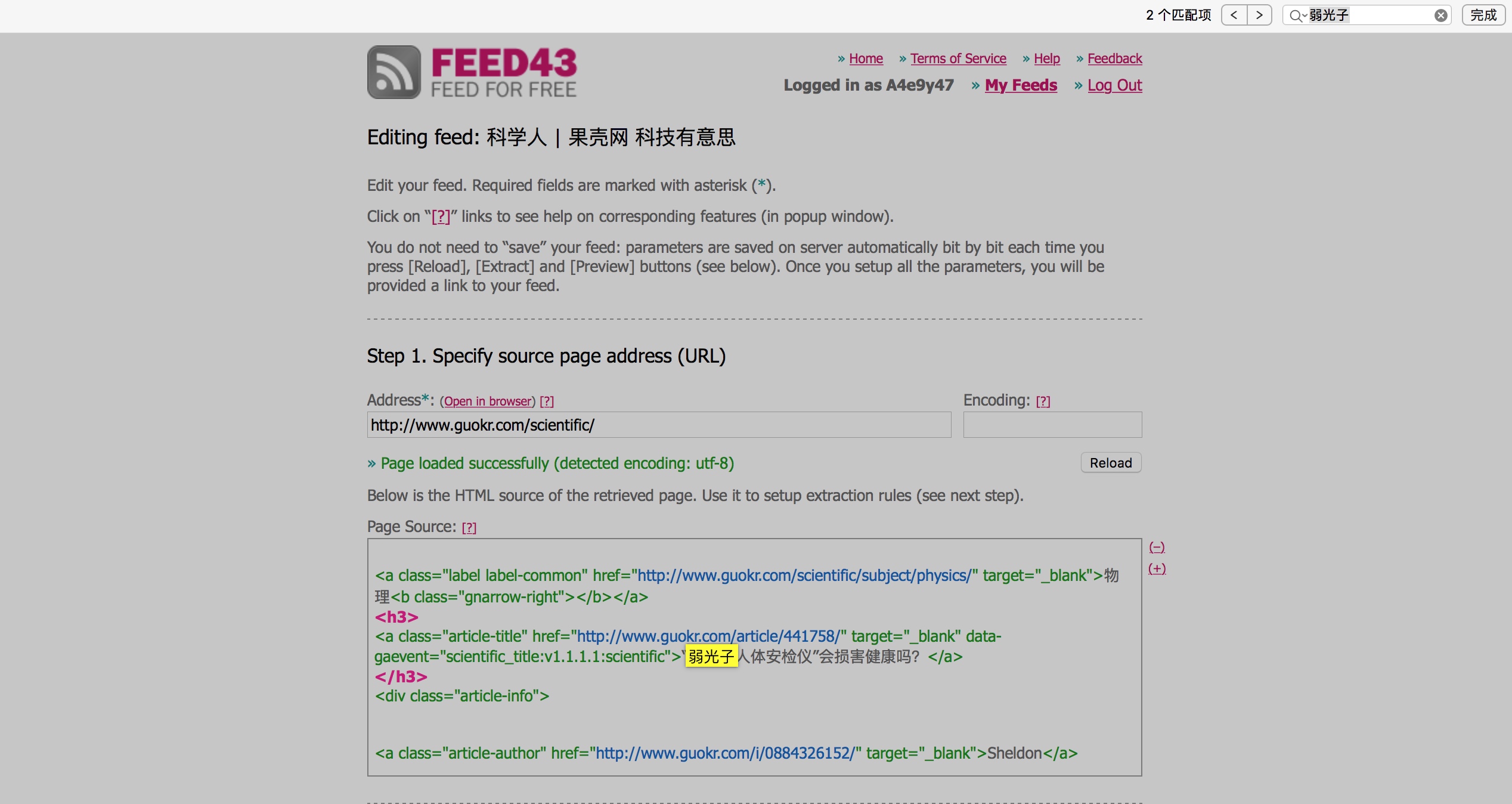
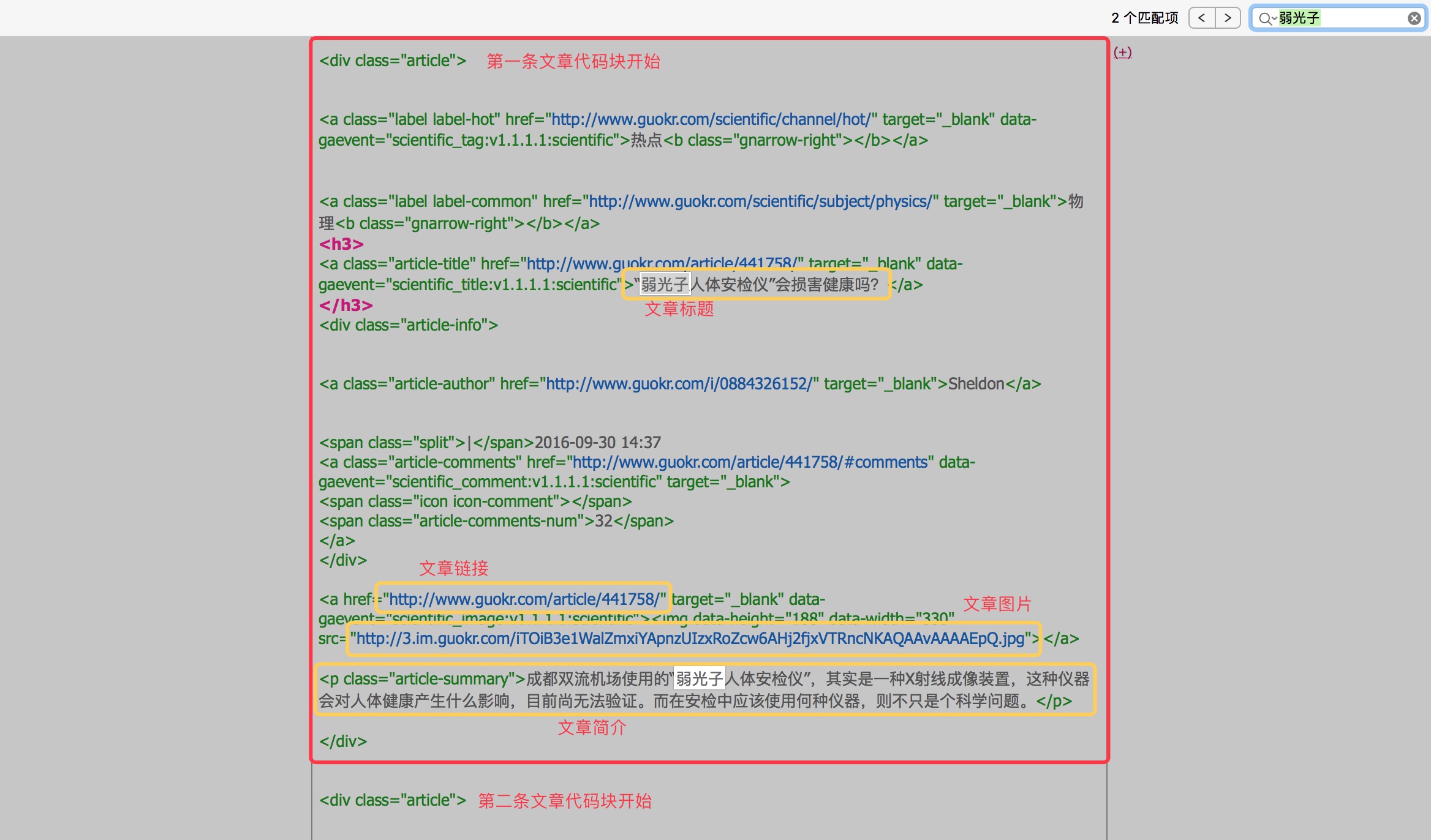
如果不容易找到文章所在的代码块的话可以搜索下一个文章标题来找到代码之间的分界点,现在总结下找到的代码。
1 2 3 4 5 6 7 8 9 10 11 |
<div class="article"> ...无关代码... <h3> <a class="article-title" href="http://www.guokr.com/article/441758/" target="_blank" data-gaevent="scientific_title:v1.1.1.1:scientific">“弱光子人体安检仪”会损害健康吗?</a> </h3> ...无关代码... <a href="http://www.guokr.com/article/441758/" target="_blank" data-gaevent="scientific_image:v1.1.1.1:scientific"><img data-height="188" data-width="330" src="http://3.im.guokr.com/iTOiB3e1WalZmxiYApnzUIzxRoZcw6AHj2fjxVTRncNKAQAAvAAAAEpQ.jpg"></a> ...无关空格... <p class="article-summary">成都双流机场使用的“弱光子人体安检仪”,其实是一种X射线成像装置,这种仪器会对人体健康产生什么影响,目前尚无法验证。而在安检中应该使用何种仪器,则不只是个科学问题。</p> ...无关空格... </div> |
你还可以用 Chrome 或其他浏览器来找到文章对应的代码块。
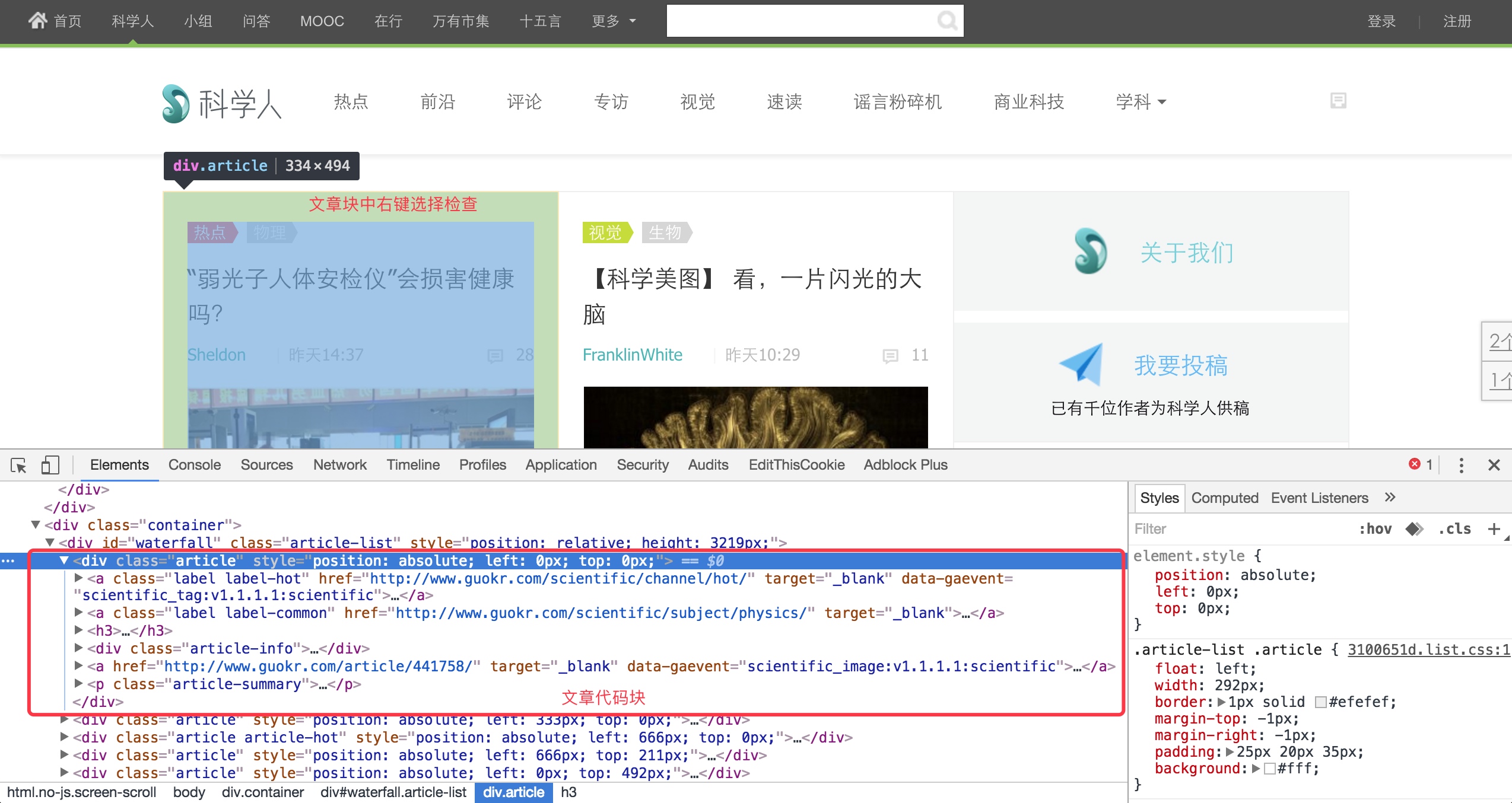
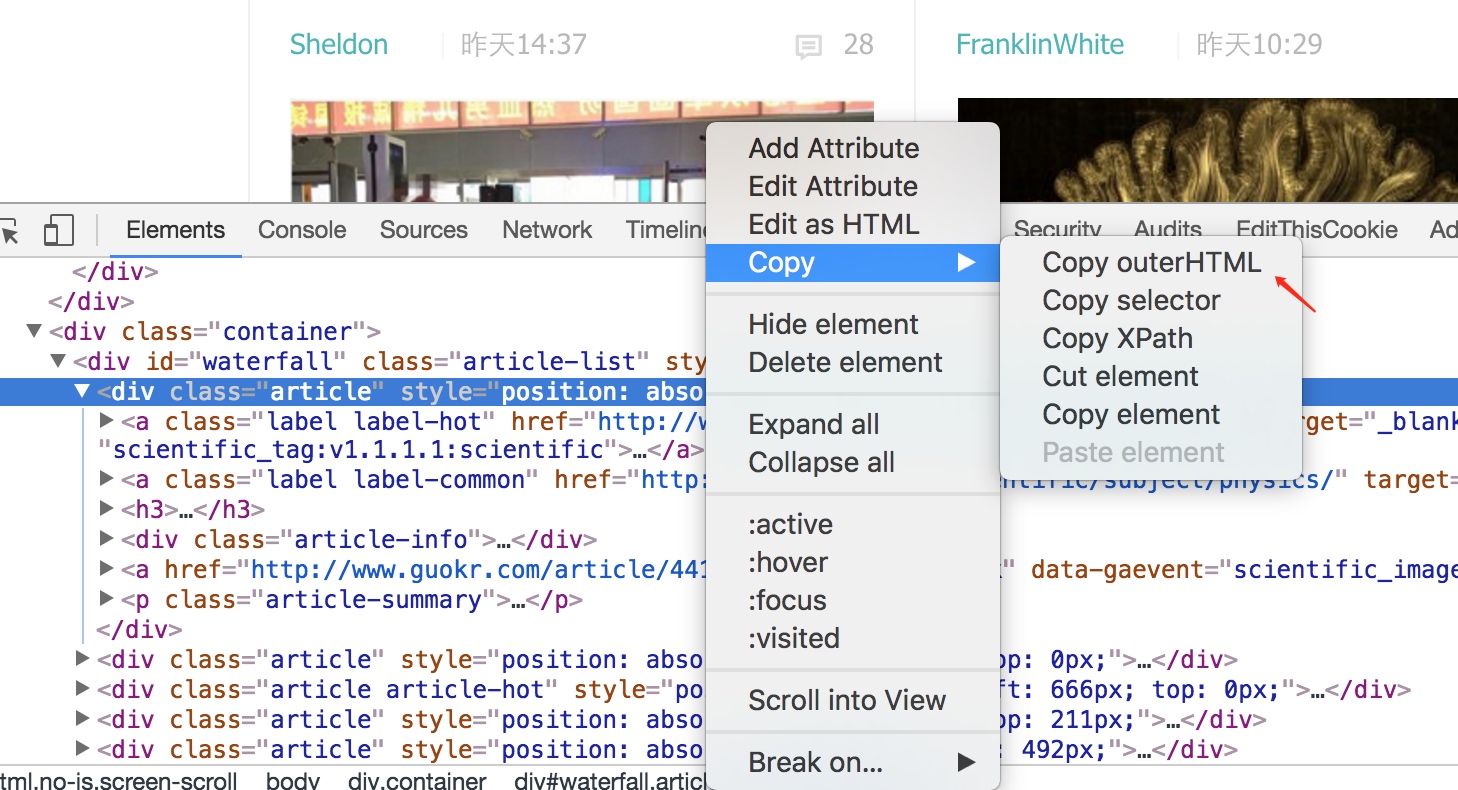
注意HTML标记符号是两两对应的,在截取的时候尽量保持完整,例如:<h3>标题代码</h3>、<a href...></a>、<p ..>简介内容</p>。
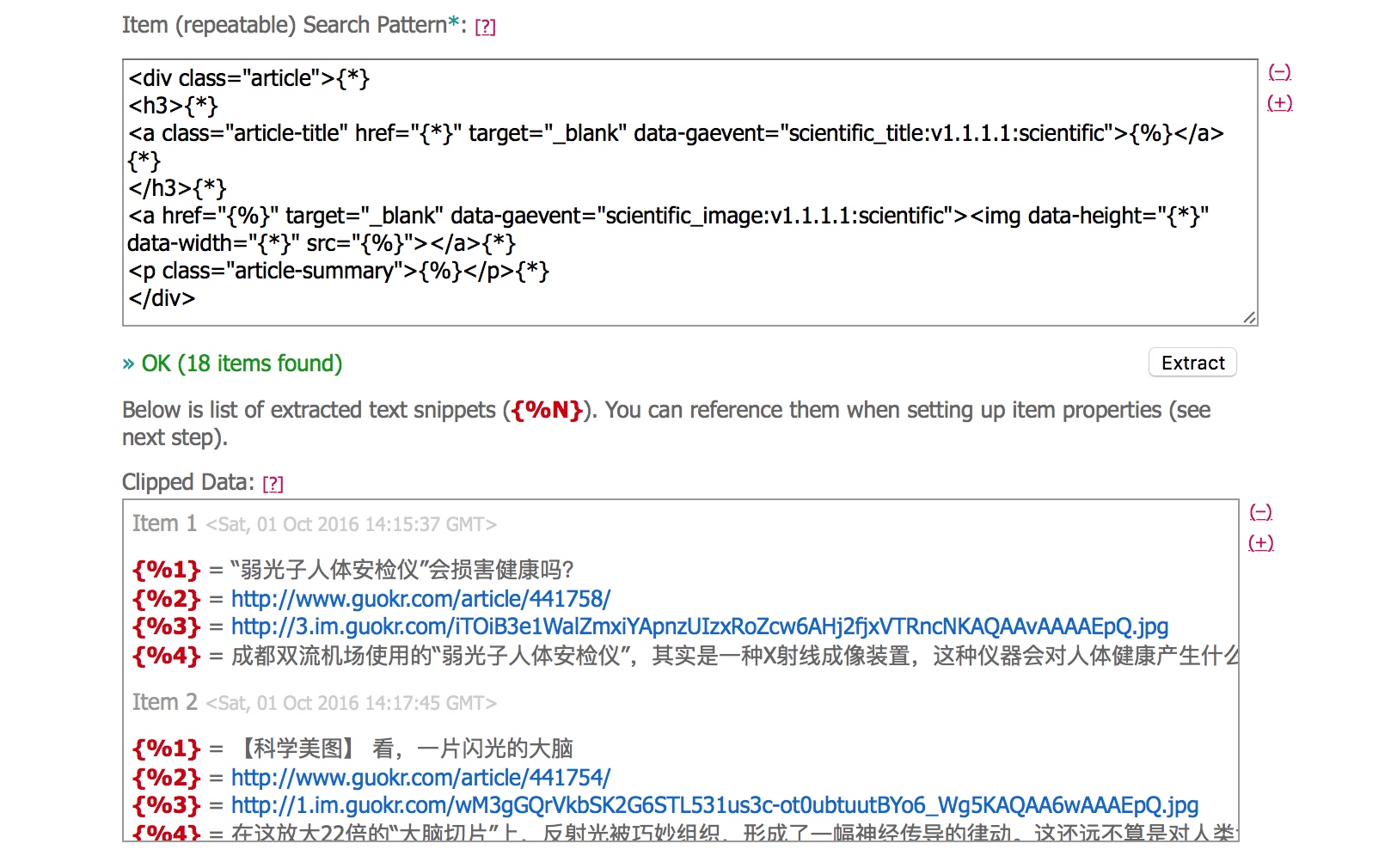
在feed43中,我们会用到两种代码块:{ % }和{*},其中{ % }替换你想获取的内容,{*}用来省略无关代码。
注意,由于文章某些发布限制,{ % }大括号中间应没有空格,如下面代码所示
替换之后得到:
1 2 3 4 5 6 7 |
<div class="article">{*} <h3>{*} <a class="article-title" href="{*}" target="_blank" data-gaevent="scientific_title:v1.1.1.1:scientific">{%}</a>{*} </h3>{*} <a href="{%}" target="_blank" data-gaevent="scientific_image:v1.1.1.1:scientific"><img data-height="{*}" data-width="{*}" src="{%}"></a>{*} <p class="article-summary">{%}</p>{*} </div> |
注意:
<div>到</div>之间就是一个层,注意保留对应文章代码块的完整- 两个标签中间有空格可以直接用
{*}代替 - 上面文章链接出现了不止一次,可以只找一个,其他忽略
- 观察代码,图片宽高不一致,所以
data-height和data-width处参数要用{*}忽略 class=""可以看作为小套路,一般代码块对应的参数都是一致的,例如标题对标题,内容对内容。- 网站中每个代码层之间可能会有冗余的空格存在(例如
<div>和下一个<div>之间),所以多用{*}替换你觉得出错的地方。(<div>...</div>{*}<div>...</div>)
点击 Extract,可以看到想要的信息都被找出来了,接下来就是用这些信息去组成RSS文章的界面。
Step 3
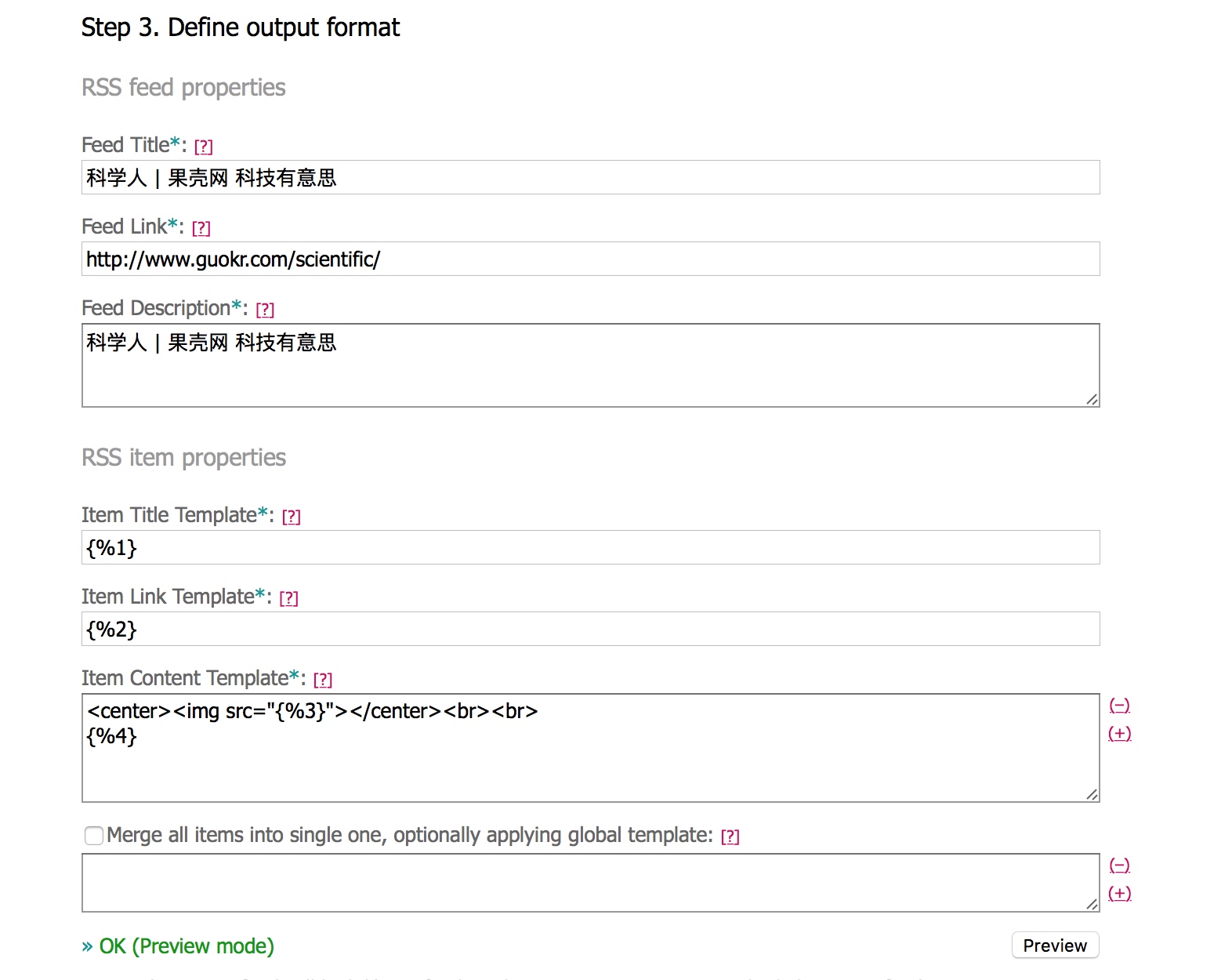
把对应的文章标题、文章链接标记块填到对应区域,当然你可以自定义每个文章的标题、链接、内容,这里我们用我们获取到的。
<center>...</center>表示居中代码块中的元素,<img src="">是图片标签,中间填入图片链接以显示图片,<br>表示换一行。你还可以在内容内再添加一个指向文章的链接,例如<a href="{ %2 }">链接显示文字</a>,更多标签可以参考HTML图片标签左下角的标签列表。
点击Preview来到 Step 4 收获成果。
Step 4
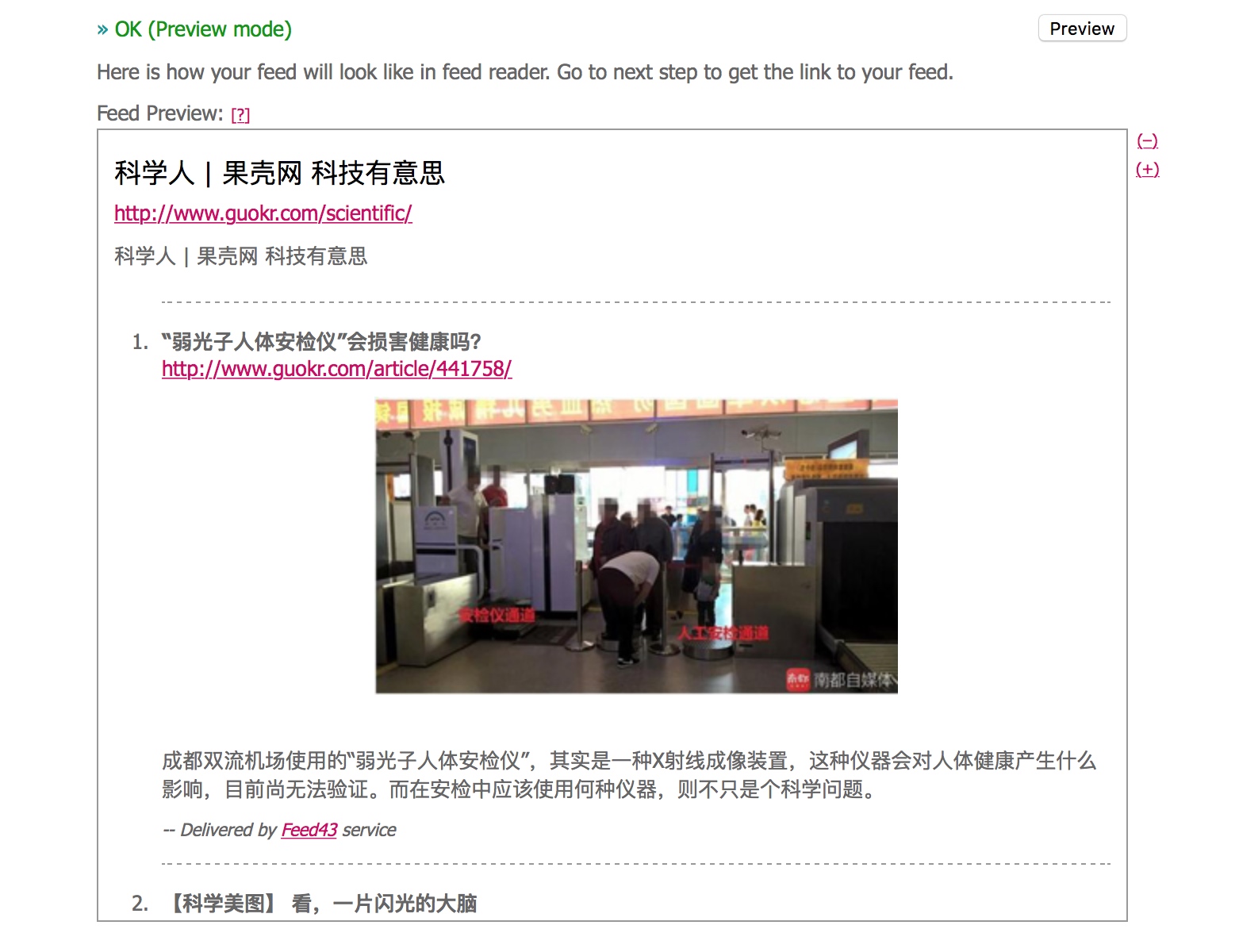
把地址添加到 RSS 阅读器上
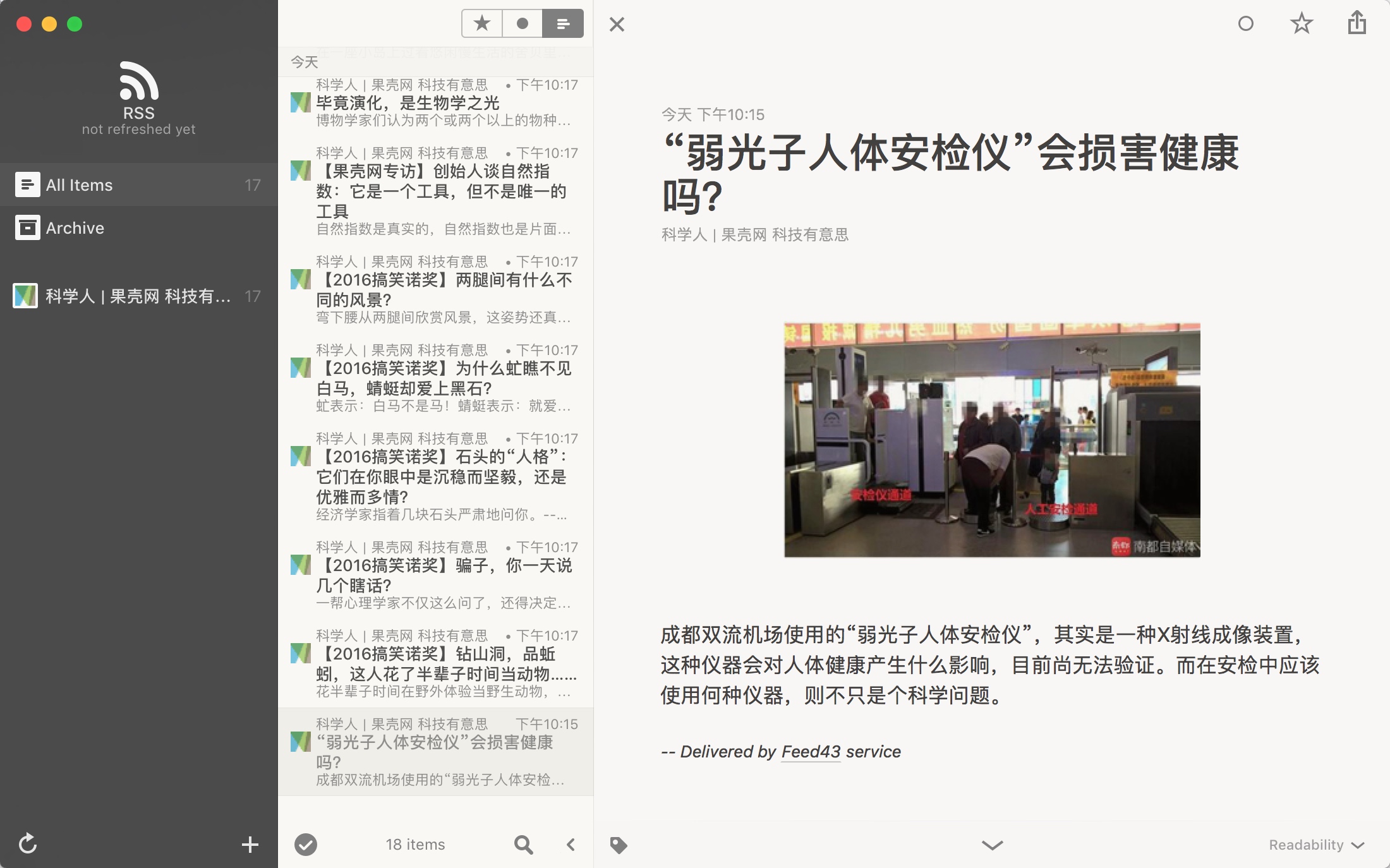
我们可以直接点击标题跳转到网页(其他阅读器可能不一样),现在说说 feed43 的注意事项。
注意
feed43 爬取限制
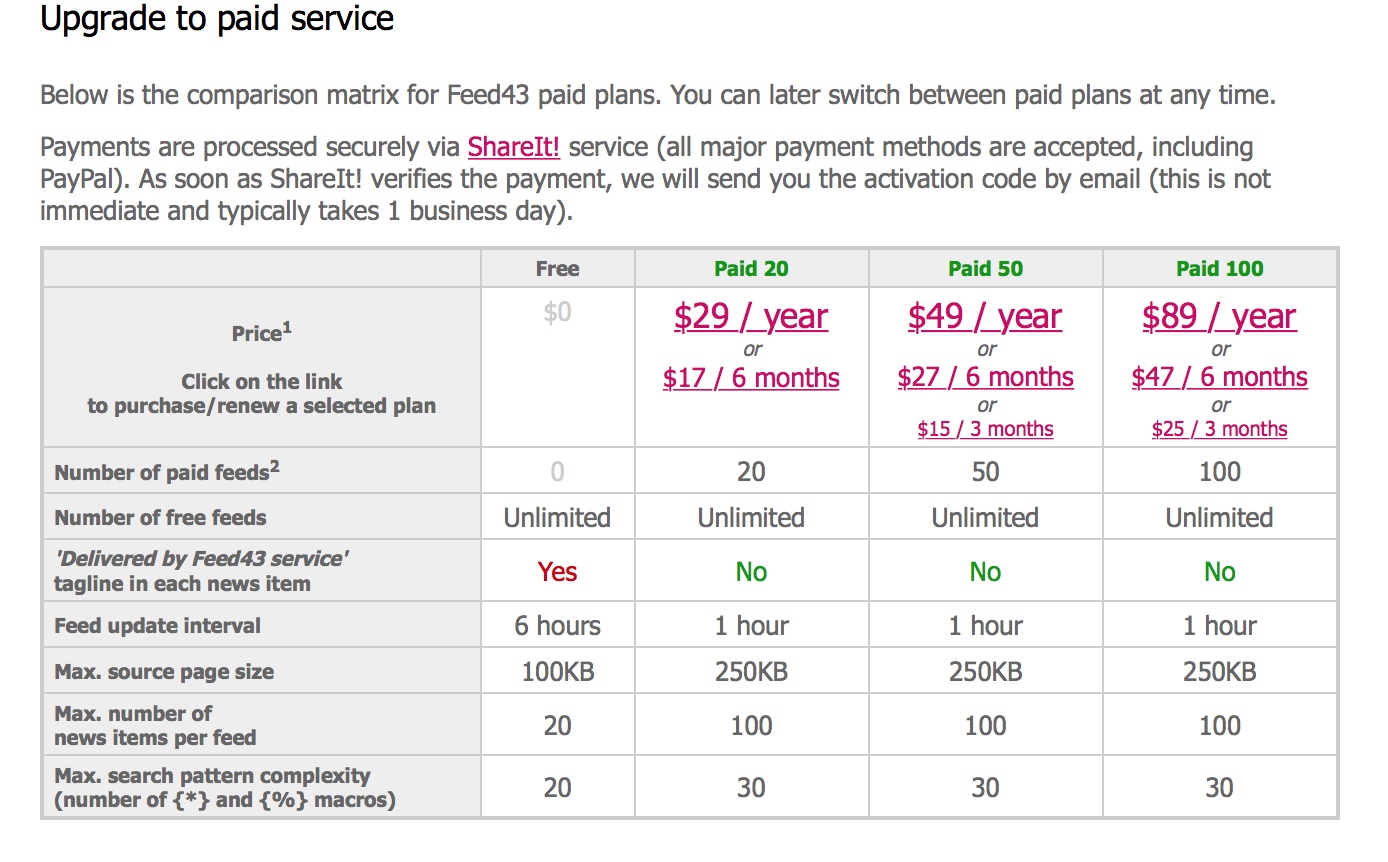
免费的计划是六小时刷新一次 RSS 地址,也就是六小时才更新一次内容,有需要的可以购买计划,不过一般够用了。
feed43 爬取失败部分原因
- 需要登录才看到内容的网页,例如一些论坛。
- 内容由 JS 方式生成
- 网站禁止了 feed43 ip 的访问,即403错误。
- 网站不支持IE浏览器
RSS 全文输出
全文输出即是直接从文章链接提取内容,并替代与链接匹配的介绍内容,例如上文中科学人文章的简介和其文章内容。我在看 RSS 订阅源内容时一般先看标题与简介,对内容感兴趣的话才去查看原文内容,我认为这也是体现 RSS 获取信息效率的一方面。这里也给出 RSS 全文输出的教程,让大家有更多选择。
Free Full RSS
这里我用 Free Full RSS 做示范。
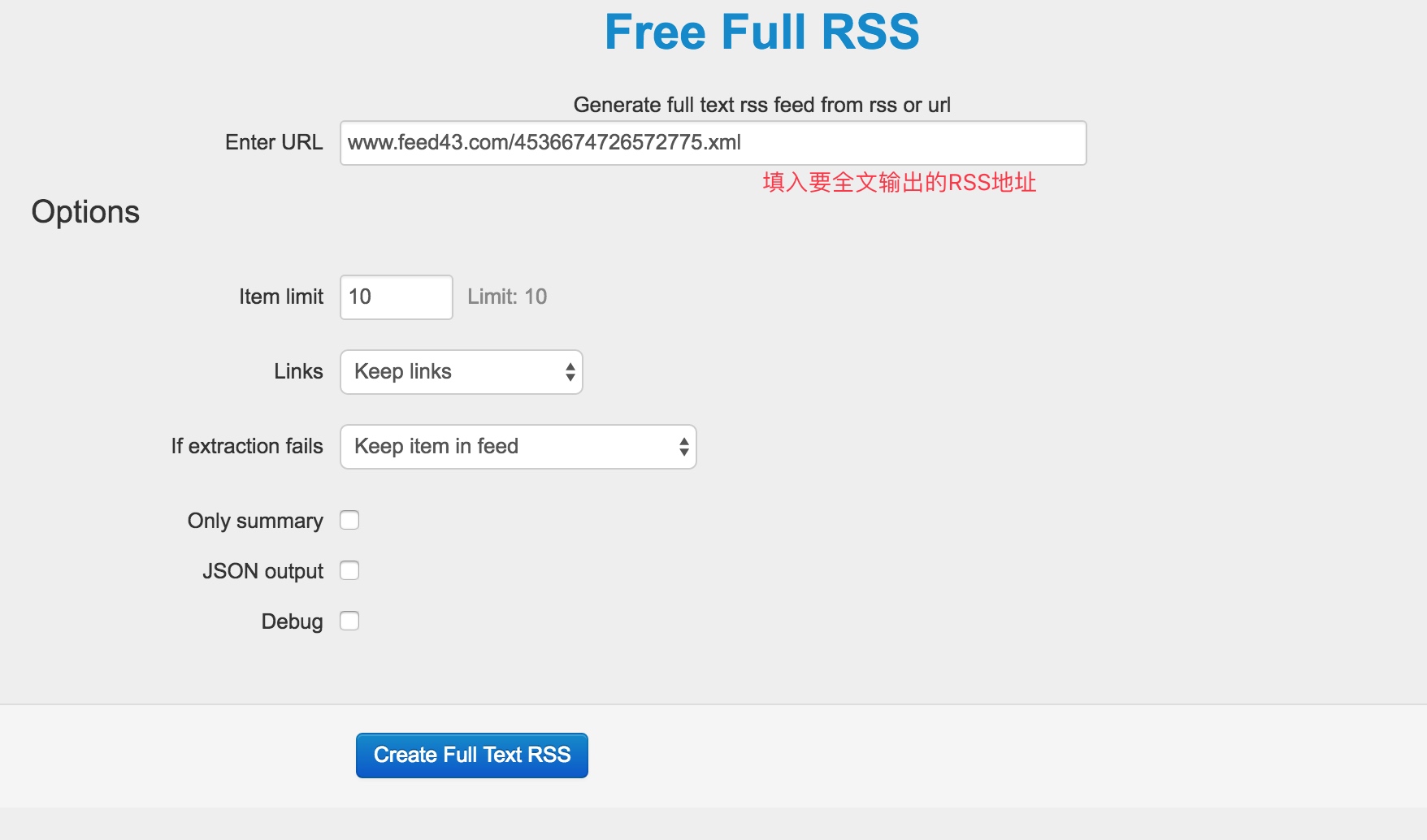
创建成功后,会得到新的 RSS 订阅地址。科学人 | 果壳网 全文输出RSS源地址

效果:

其他全文输出网站
| 名称 | 网址 |
|---|---|
| Full Text RSS Feed Builder | 完全免费 |
| fivefilters | 抠门的免费计划,有付费计划。 |
| FULL CONTENT RSS | 限时免费 KEY,过时失效 |
自制 RSS 源用途
学会了制作 RSS 源,那么我们能做什么有趣的事情呢?!
订阅自己关注的网站、有价值的博客、买买买信息、政府机关部门(?)、播客等等。
例如自己用 Feed43 做了些 RSS 源:
缺书网来获取买书优惠信息,RSS 源地址。
图灵社区关注新出版的技术书籍,RSS 源地址。
想要了解更多关于 RSS 可以看看这篇文章 使用 RSS 可以做什么你未曾想过的事。
总结
2013年 Google Reader 关闭,谷歌给的原因是用户流失,这最主流的RSS阅读器的退出似乎说明了 RSS 已经快要成为一个过时的阅读方式。这种阅读方式减少了网站和用户之间的交流,也不太适应短信息的节奏(想想你会用 RSS 刷微博吗?)。往大了看这是当今社会的节奏,人们更喜欢刷微博、刷朋友圈。海量的碎片信息会导致人们喜欢浅浅尝一口,而缺少深度的思考,逐渐迷失在海量的信息流中。生活离不开阅读,我们可能不能变成万事通,但我们可以更有效率地去获取自己想要的信息。
如果你看到这,或许可以考虑尝试下这种阅读方式?RSS 源贵精不贵多,先养成习惯,并判断这些信息对于自己的价值。
另外如果你根据本文成功创建了自己的 RSS 源,或者有疑问,请在本文评论中告诉我,欢迎分享你的 RSS 地址和经验。
原文链接:http://frankorz.com/2016/10/01/rss-tutor/